Foundational Mechanics
How verification loops, drift, and inconsistency quietly remove your facts from AI answers
Your pages validate. Your entities are crawlable. Yet when an AI answer renders, your facts still do not appear. This is why AI does not trust your content. The issue is not visibility anymore; it is verification. Modern systems do not “trust” in a human sense. They reconcile signals, compare versions, cross-check against other sources, and include only what survives conflict checks. If your facts fail those verification steps, they are down-weighted, ignored, or quietly replaced.
Why AI does not trust your content: the verification loop (Four R’s)
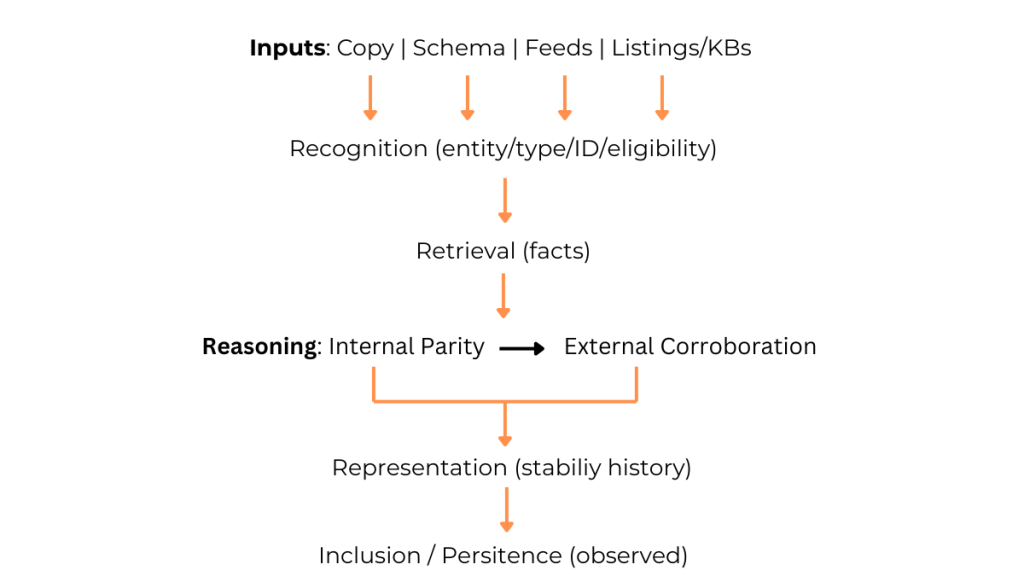
This section breaks down the most common reasons models exclude or down-weight facts after the verification loop, using the Four R’s framework (Recognition, Retrieval, Reasoning, Representation). For a deeper explanation of the framework itself, see Optimizing for AI: Why Most Brands Fail.
- Recognition — Detect the entity, map it to a known type, resolve duplicates, and confirm eligibility (canonical IDs, stable URLs, template/slot mapping).
- Retrieval — Pull candidate facts from copy, structured data/markup, feeds, and external listings/KBs. This is why Google’s structured data documentation matters.
- Reasoning — Run internal parity (schema ↔ on-page), then external corroboration (other surfaces). Many modern systems implement checks inside pipelines inspired by retrieval-augmented generation and selection heuristics like self-consistency.
- Representation — Prefer facts with stable meaning and values across time and surfaces; persistence and selection stability are the observable outcomes. For large sites, long-term stability also aligns with Google’s crawl budget guidance.
Why do facts get dropped from AI answers?
- Recognition gaps: ambiguous entities, shifting canonicals/IDs, or template fields reused for different meanings.
- Parity breaks: on-page says “sleeps 5” while structured data or a secondary surface implies “4.”
- Cross-surface drift: product feed, Google Business Profile, and site copy diverge after a partial update.
- Nulls and defaults: required attributes publish as empty or “TBD,” degrading downstream selection.
Micro-example
- Day 0 (conflict): Model page copy claims “sleeps 5.” Structured data has seatingCapacity=4. Business listing shows “4 seats.”
- Loop behavior: Recognition ties all sources to the same entity; Retrieval gathers both values; Reasoning flags the mismatch; Representation has no stability history favoring “5.”
- Outcome: the answer omits capacity or defaults to the corroborated 4; the “sleeps 5” claim is excluded.
- Fix (Day 1): align copy + schema + listing to the same value (either 4 or 5), with identical wording and numeric value across surfaces.
- Result (Day 7–30): capacity appears and persists in answers; churn drops.
Operating model: two lanes, both “block on fail”
To keep facts stable, your workflow needs guardrails. The two-lane model below catches drift before it ships.
CMS lane (no-code / low-code)
- Define required attributes per template (minimum three).
- Block publish if any required field is null/placeholder.
- Live parity checks: required fields in copy must match the same fields in schema (e.g., JSON-LD). Reference formats: JSON-LD and Microdata.
- Freeze canonical and primary IDs on minor edits; require explicit confirmation to change.
- Show a “stability history” panel for each entity (last 10 changes to required fields).
Engineering lane (CI/CD)
- Pre-merge checks must fail the build when:
- Schema missing on required templates.
- Schema invalid or parsable but empty for required fields.
- Parity diff ≠ 0 for required fields (copy vs. JSON-LD/Microdata).
- Canonicals/IDs change outside a migration script.
- Redirect loops or status-code regressions on key URLs.
- Schema missing on required templates.
- Continuous Integration basics if you need a primer: Martin Fowler on CI.
- Post-deploy job: sample pages, recrawl, and log parity deltas; page ships only if delta=0 for required fields.
Which metrics actually track inclusion and stability?
Inclusion is observable. These metrics help you measure whether facts survive representation over time.
Keep these:
- Inclusion rate: % of targeted facts/entities that appear in AI answers for their query set.
- 30-day persistence: share of included facts that remain included across refreshes (selection stability under Representation).
- Drift incidents: number of parity or cross-surface conflicts detected per month.
- MTTR (facts): median time to resolve a drift incident.
Add these:
- Schema coverage: % of key templates with all required fields populated (not just present).
- Parity error rate: % of releases that introduce a required-field mismatch.
- Cross-surface conflict count: number of entity attributes with inconsistent values across site, feed, and listings.
- Answer share by query cohort: among tracked queries, share of answers that include your governed facts.
Implementation quick start
If you want to operationalize AEO without building new tooling, start with these baseline rules.
Required attributes (example set; adapt per template):
- Identification: name, canonical URL, primary ID.
- Core facts: seatingCapacity (or equivalent), price/priceRange, areaServed or availability.
- Governance: lastVerified date, sourceOfTruth tag.
CMS “block on fail” rules:
- Required fields must be non-null, non-placeholder, and consistent across copy + schema.
- Publishing is blocked if parity diff exists on any required field.
- Warn on any change to canonical/ID; require explicit confirmation.
CI “block on fail” checks:
- Schema present + valid + populated.
- Parity diff = 0 for required fields (regex for copy vs. JSON-LD values).
- Canonical stable unless migration flag present.
- No critical link/redirect/status regressions on key URLs.
Close
Indexing gets you seen. Verification gets you included and kept. This is the real reason why AI does not trust your content when your facts drift or contradict themselves. Govern the fields that matter, stop mismatches at publish time, and track persistence instead of presence. Stability compounds. Churn does not.
- Recognition: detecting the entity/type, resolving duplicates, stabilizing canonical IDs/URLs, and confirming eligibility.
- Retrieval: collecting candidate facts from copy, schema, feeds, and external sources.
- Reasoning: internal parity checks and external corroboration to down-weight conflicts; see RAG and self-consistency for adjacent mechanisms.
- Representation: stability of a fact’s meaning and value across time and surfaces; persistence is the observable outcome and benefits from crawl-budget-aware change management.
- Parity: required fields in copy and structured data carry the same values/meanings; formats like JSON-LD and Microdata are both valid.
- Drift: unintended change to a governed fact (value, format, or surface) that breaks parity.
- Inclusion rate: % of tracked facts/entities that appear in answers for their query set.
- Persistence: % of included facts that remain included over a defined period.: unintended change to a governed fact (value, format, or surface) that breaks parity.
- Inclusion rate: % of tracked facts/entities that appear in answers for their query set.
- Persistence: % of included facts that remain included over a defined period.